DB Transactions : Isolation Levels #
Introduction #
In Anomalies we talked about anomailies in DB transactions, and in this section we will be discussing about how to avoid these anomalies by enforcing different Isolation Levels.
Modern Databases mainly support following 5 types of Isolation levels,
- Read Uncommited
- Read Commited
- Repeatable Read
- Snapshot
- Serializable
And Here is the summary of supported isolation levels in few modern databases,
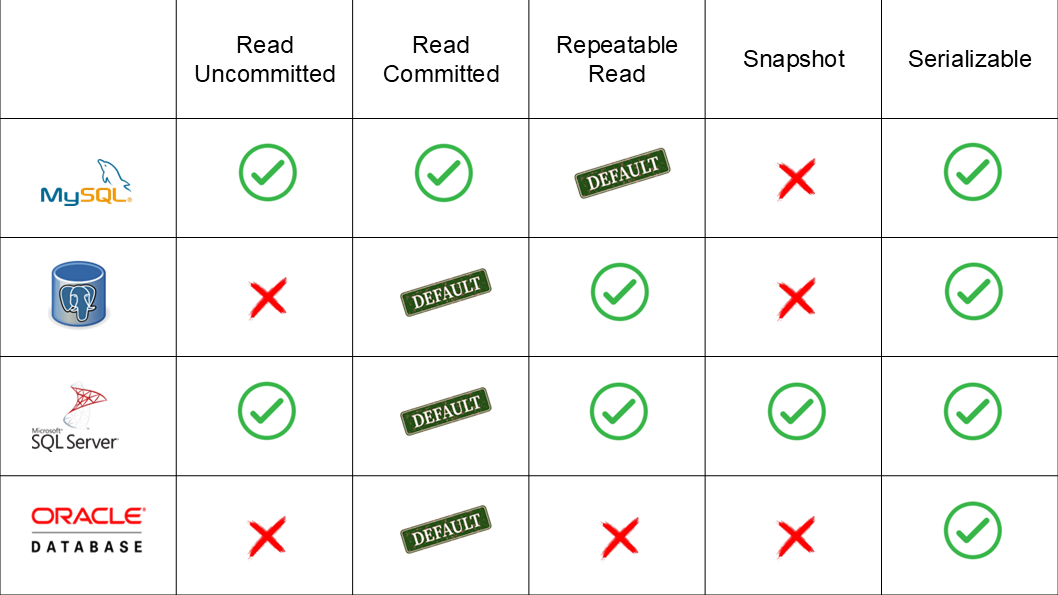
Now we have a basic understading of isolation levels and it’s compatibality with different databases. Now let’s discuss each one by one.
MVCCStands for Multi Version Concurrency Control, which is database optimization technique creates duplicate copies of records so that data can be safely read and updated at the same time by multiple transactions without blocking each other.
Read Uncommited #
This isolation level allows a transaction to read uncommited changes done by other transactions.
Due to this, anomalies like dirty reads, non repeatable reads and phantom reads can occur.
How Implemented At Database Level :
-> DB does not aquire any locks or
-> Does not check whether data is commited or not.
Changes done by transactions are immediataly visible to other transactions, regardles of commited or not.
Read Commited #
In this level of isolation, Database make sure that it allows a transaction to only read commited changes done by other transaction. Uncommited changes done by other transactions won’t be visible. This prevents anomalies like dirty reads. But non repeatable reads and phantom reads still possible.
How Implemented At Database Level :
-> MVCC-Based Implementation : each query in a transaction sees a snapshot of commited data, up to starting time of that specific query.
-> Locked Based Implementation : readers aquire shared locks on reading rows to make sure no one modifies them till reading finished. Writers aquire exclusive locks on rows they update to prevent other trasactions from reading uncommited data.
Each time a query runs within a transactional context, It only sees commited data upto starting time of that speicific query.
Repeatable Read #
It makes sure that if a data row read within transactional context, every query in that transaction only see updation done to that data row only by that specific transaction only. Changes done by other trasactions to this data row will not be visible within this transactional context.
This prevents anomalies like dirty read and non repeatable reads. But phantom reads is still possible.
How Implemented At Database Level :
-> MVCC Based Implementation : If transaction read rows 10-30 –> it will be provided a own snapshot of rows 10-30, and it will see/update same snapshot during the transaction.
-> Lock Based Implementation : If transaction read rows 10-30 –> it will aquire a shared lock for those rows, to make sure no other transactions update those rows [1].
[1] Note : These shared locks are applied for each rows, but not to the row range, so this does not prevent against insertion of new rows to the range. Which means
phantom readsstill possible.
If data read at some point of transaction, Those data will not be changed after the time of that first read to end of transaction, due to updations done by other transactions.
Snapshot #
As mentioned before, Repeatable Read gurantees all queries in the transaction will not see the changes done to a row by other transactions commits, after it read data row for first time in the transactioanl context. This means,
- If
Query 1ReadR1,R2,R4at timet1-> transaction will be blocked from seeing changes done toR1,R2,R4by other transactions after timet1. - If
Query 2ReadR3,R5at timet2-> transaction will be blocked from seeing changes done toR3,R5by other transactions after timet2.
So rows will be snapshot/locked on different times, based on how it retrieves first.
However Snapshot make sure,
Data will be snapshot at very beginning of transaction. Not based on retrieval time, but based on start time of whole transaction.
This solves anomalies like dirty reads, non repeatable reads and phantom reads.
How Implemented At Database Level :
-> MVCC Based Implementation : Transaction will be provided it’s own snapshot at begining of the transaction, and it will see/update same snapshot during the transaction.
-> Lock Based Implementation : Transaction will acquire a shared lock for data at begining of the transaction, and make sure no other transactions update data, during the transaction.
Serializable #
This is highest level of isolation. This makes sure transactions act like excuted one after another (like sequentially, not concurrently).
This solves anomalies like dirty reads, non repeatable reads and phantom reads.
How Implemented At Database Level :
-> MVCC Based Implementation : Each transaction will be given a snapshot and it can proceed with that. However during commit time, it checks data updated by oher transactions and do validations. If conflicts found transaction will be rollbacked.
-> Lock Based Implementation : The database transactions aquire a rangelock (not for each row, but for complete range) to block updates that can affect the transaction. This ensures no new rows added, by other trasnactions, which prevents phantom reads.
This mechansim make transactions to work like those were exeuted one after another, sequentially.
Summary #
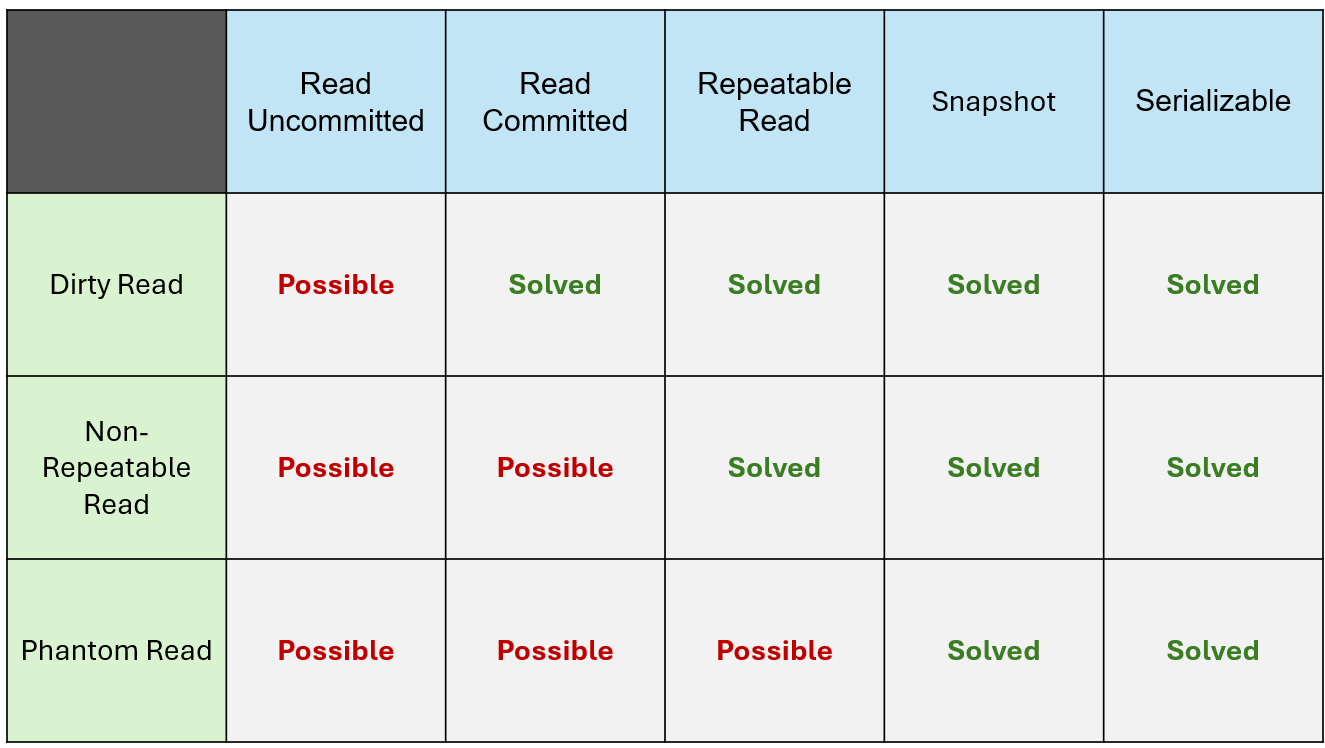
Yeah That’s all about isolation levels and anomalies for now.
Hope this article was helpful.
Thank You.
Happy coding 🙌