System Design: Real-Time Chat Application #
In this article, we will discuss how to design software architecture for a real-time chat application with robust features. To gain an overview of where we’re heading, I’ll start by presenting the final architecture diagram below.
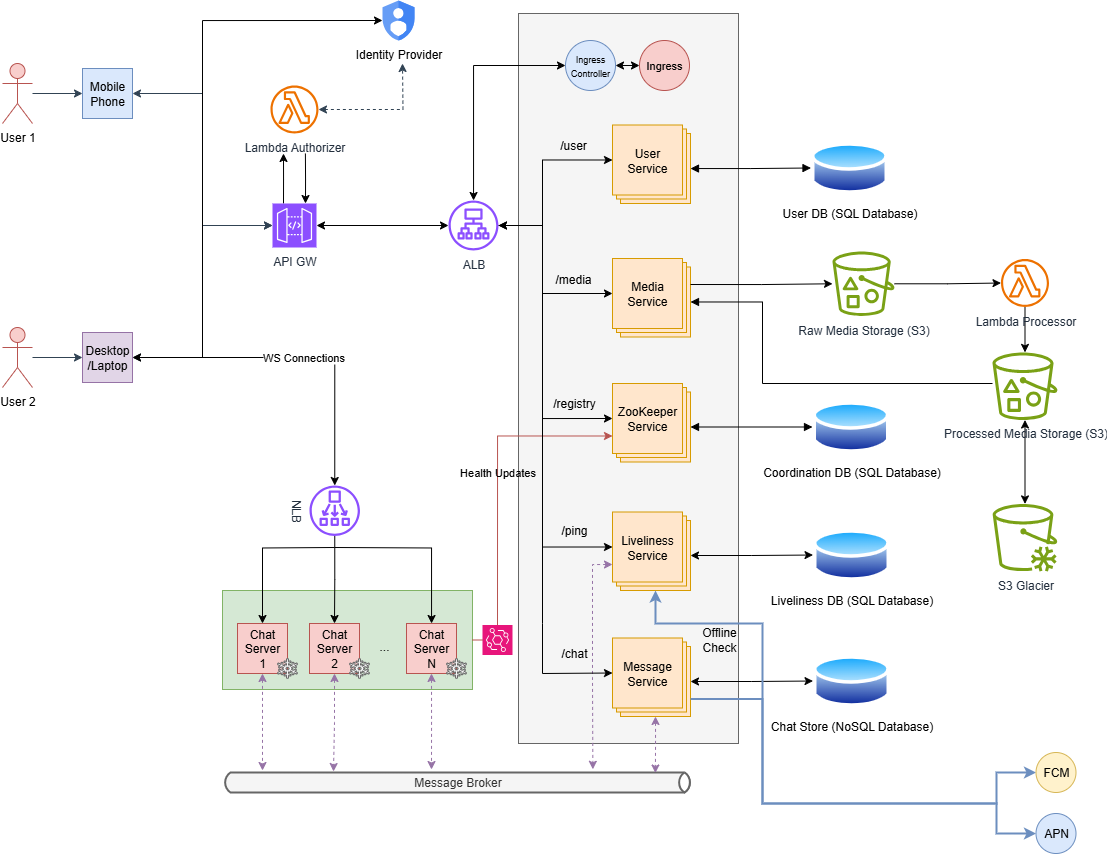
Now, let’s discuss how the above architectural diagram was built, starting from minimal architecture.
Level 1 #
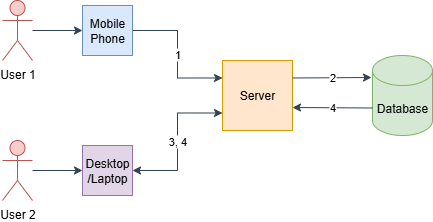
First, let’s try to develop a very basic mechanism where users can put messages into the system and get them from there.
Assume our application has two types of users,
- Mobile App Users
- Desktop App Users
As presented in the above diagram, first, a user can publish a message (1) into the system, and the application will process it and store it in the database (2). Meanwhile, another user can long poll and see whether he/she received any new messages (3). If there are new messages, the long poll request will be handed over the new message, so the user can view that in the application.
Level 2 #
However, there are a few issues with this approach. This will work as long as we have only a small number of users, which means this solution cannot be scaled. As the next step, let’s try to scale this solution.
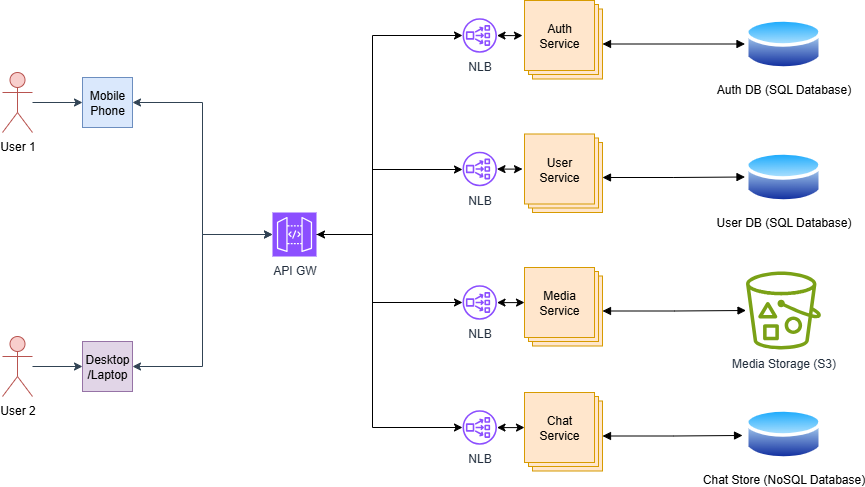
Here, we have introduced microservice architecture to robustly handle a large number of users.
In this microservice architecture, Business logic is divided into separate services, such as authentication is handled by the Auth Service, user data is managed by the User Service, files/images and other media-related activities are handled by the Media Service, and chat message data is handled by the Chat Service.
And each service group owns its own data structure and databases based on the nature of the data. For example, authentication and user-related data can be easily handled using SQL databases. However, media-related data should be stored in an object storage like AWS S3. Since chat messages are mostly unstructured (can have links, images, videos, texts, mentions), we are using a NoSQL database to store them.
Since we have multiple services for a given service group (For example, 3 User Services handling requests in the User Services Group), we have attached a Network Load Balancer in front of each service group.
All these services are exposed via a single API GW; users do not need to worry about what happens behind the scenes. Since API Gateway is a robust component that handles,
- Rate limiting & throttling
- Cache
- Logging and Monitoring
- HTTPS/TLS Termination
- Request Validation
And so on.
In addition to the above, we can route requests to specific Service Groups’ NLB using path prefixes such as
- /auth/* => Auth Services Group
- /user/* => User Services Group
- /media/* => Media Services Group
- /chat/* => Chat Services Group
Level 3 #
However, we are missing some Cost Optimizations and Best Practices Here. Now let’s try to fix them. Let’s try to implement some.
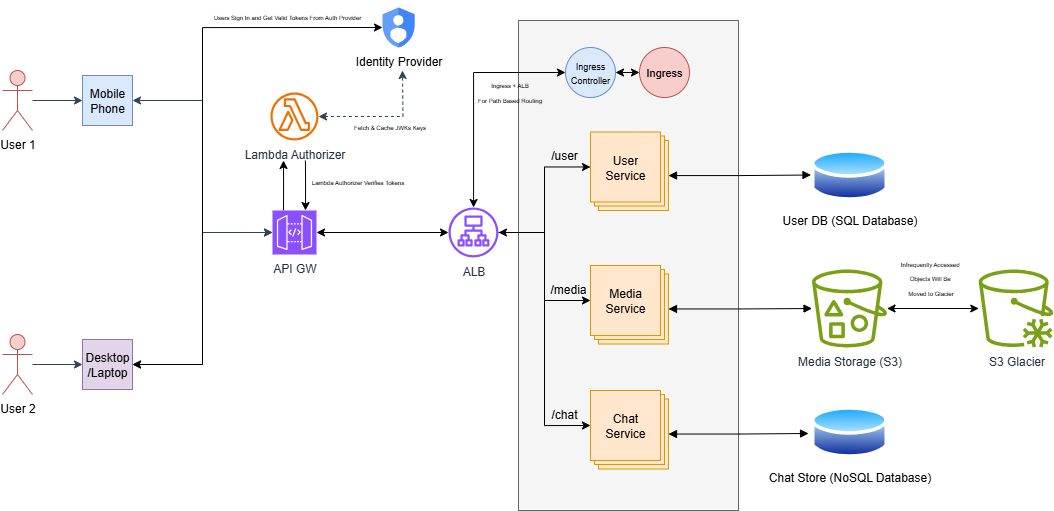
- Using separate NLBs for each service group is costly and not recommended and is costly with many NLBs. Instead, we can use ALB along with an Ingress Controller to then handle the load balancing and path-based routing. The traffic will flow like,
User => API GW => ALB + Ingress (path-based route) => Service (load balance between pods) => Pods
-
In a chat application, users are mostly engaged with current situations. Due to this, there is a low probability that a user will revisit a photo/video shared a few years ago. This means we can introduce a lifecycle policy to move less frequently used media files to low-cost storage like S3 Glacier, which reduces cost significantly.
-
Also, it is costly to develop our own authentication mechanism and requires following a large set of security & privacy rules and regulations to comply with standard authentication mechanisms. In this case, we can use some federated authentication to handle the user authentication process.
-
Also, we can get rid of the auth service and reduce internal calls to validate the tokens if we do the authentication at the API Gateway Level.
Level 4 #
Now let’s focus on a few more improvements.
-
Our current system is working based on a long poll mechanism, where users create long-lived HTTP requests and try to get new messages if they arrive. However, this approach wastes resource usage unnecessarily, both from the client and server sides. As a solution to this, it is recommended to use a lightweight full-duplex stateful protocol like WebSocket.
-
Our application has many chat servers, which handle multiple messages at a time, and unique IDs & timestamps are attached to each message before being stored in the DB. Due to the large number of messages, there can be ambiguity in the ordering of messages sent and received, even at millisecond levels. This is why we need to use Snowflakes for the ID generation algorithm, where each chat server can generate a robust, unique ID upon the arrival of a message. Since we are using Snowflakes, all timestamps, machine IDs, and sequences are integrated into a 64-bit Unique ID, which can be used to sort messages based on time. This saves space also, because we don’t need a separate time field, and this only takes 64 bits, which is lighter than UUIDs (takes 128 bits).
-
Besides all, we need a service that periodically gets updates on chat server status, keeps a record of them, and points users to a more eligible chat server available, and also keeps a record of which user connected to which chat server, vice versa. We call this service ZooKeeper.
-
Since we are using WebSocket, NLB will be the best candidate for the Load Balancer, which routes based on IP Hash. This can handle a large number of Web-Socket connections efficiently.
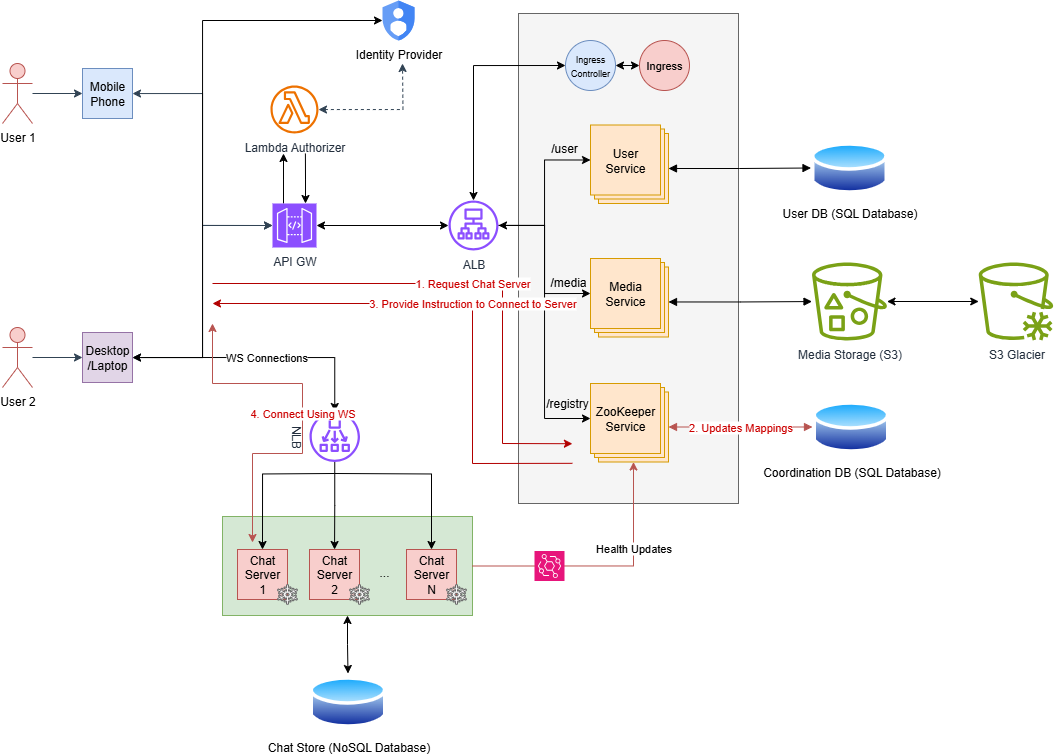
Level 5 #
However, there is an issue with the current approach. In our current approach, chat servers need to query from database for each and every new message, which puts a heavy load on both servers and the DB itself.
To avoid that, we can use a message broker to decouple this syncing. Storing messages will be handled by a separate service called the Message Service, not by the Chat Services. Here’s how it works,
Assume UserA is interested in chats from UserB, UserC, and GroupA. Once UserA connects to Chat Server 1, it subscribes to events like,
- UserB:newMessage
- UserC:newMessage
- GroupA:newMessages
- …
Now, assume UserB connected to Chat Server 2 and published a message. Chat Server will put this message into the message broker with topic UserB:newMessage. Since Chat Server 1 is already subscribed to this event, it will be notified about this event and will send that to UserA through the active Web-Socket connection.
By default, the Message Service is subscribed to all newMessage events. Due to this, it will receive all these new messages from users/groups and store them in the DB.
This way Chat Server needs to handle real-time messages only.
When UserA disconnects the socket, Chat Server 1 can unsubscribe from the subscribed topics if no other socket is interested in them.
If the user wants to see old messages or details about a specific message, the exposed relevant endpoint by the Message Service can be used.
This way the application can handle both real time and old messages robustly.
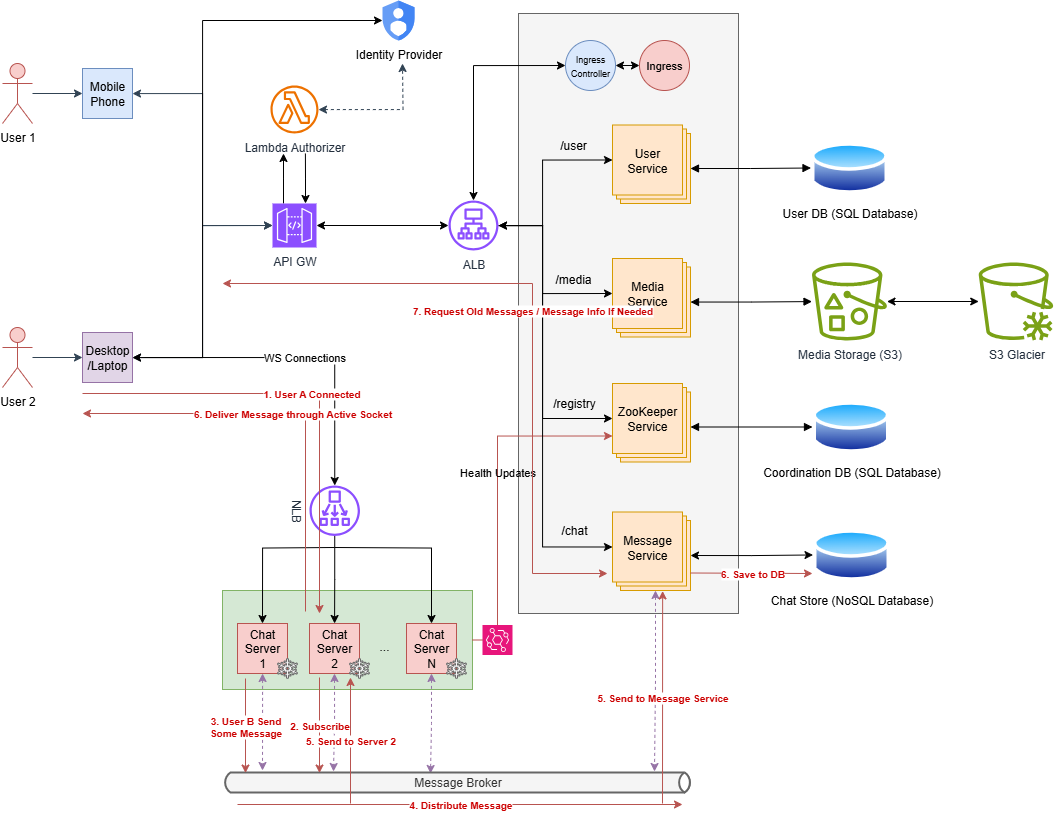
Level 6 #
Now the system can handle both real-time and old messages robustly. But we can add more features such as online/offline status and push notification for new messages when the user goes offline.
To implement online/offline status, we need a new service called Liveliness Service. This service exposes an endpoint, where users will send a heartbeat periodically. We can implement logics such as,
- If 1 heartbeat received: Mark Online in DB
- If skipped 3 heartbeats: Mark Inactive in DB
- If skipped 5 heartbeats: Mark Offline in DB
Any updates in this liveliness status will be published into the message broker, where interested Chat Servers can grab them and send them to the relevant interested users.
For sending notifications, we can add one more logic to the Message Service, such as if the user is marked as offline in the Liveliness DB, while saving the message to the DB, then send a notification using FCM / APN.
In addition to this, we can introduce a new Lambda for media processing. First, user uploaded files will be put into Raw Media Storage, then Lambda will be triggered, and it will start processing these new media files. Then, processed files will be stored in Processed Media Storage for long-term retention. This lambda can be used to,
- Media Format Validation & Conversion
- Media Compression
- Scan Media
- Read Metadata
- Generate Preview etc.
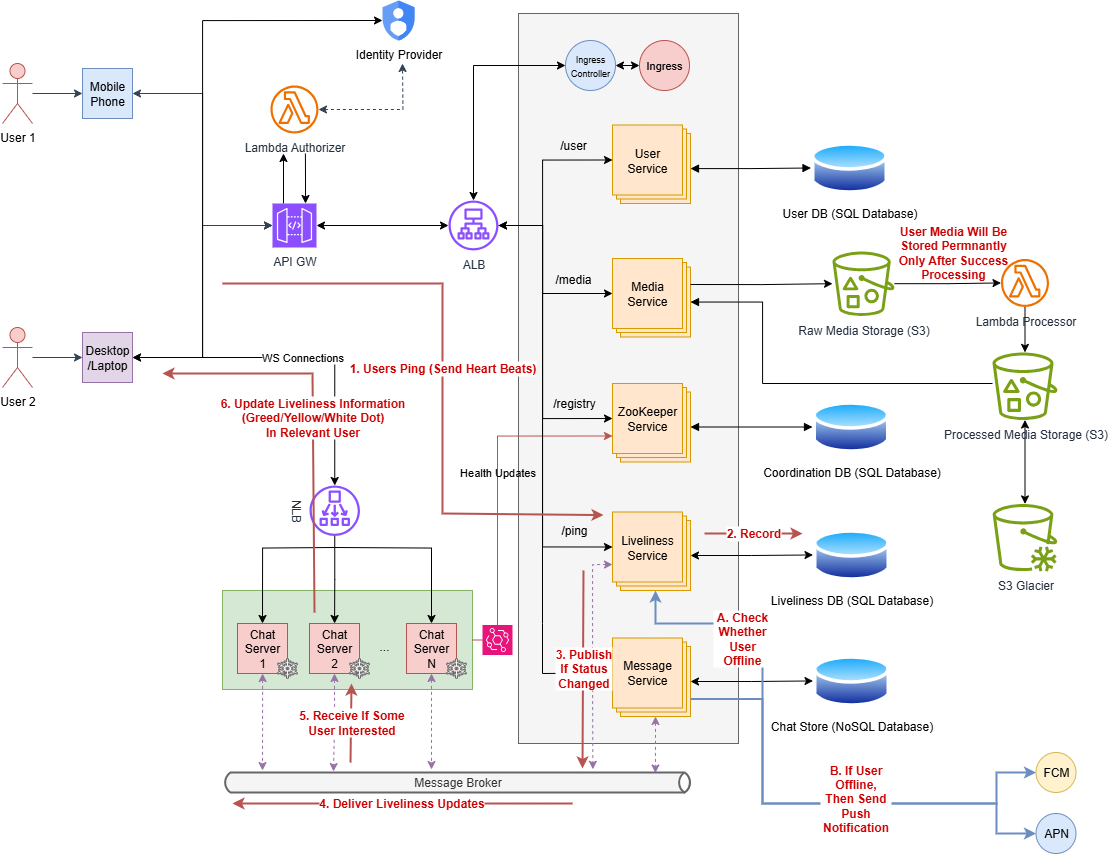
Here is the current architecture of the system,
This architecture can be further improved by introducing,
- CloudFront / CDN
- Analytics
- Machine Learning
- …
However, for this article, I’ll stop here for now. Hope this was helpful.
Thank You !
Happy Coding 🙌